
*데이터 컨설턴트 Harshit Tyagi의 프리코드캠프 기고글을 번역했습니다.
사실 그냥 숫자가 바뀌는 것 뿐일지도 모릅니다만, 새해가 되면 사람들은 무언가 새로운 것을 시작하려는 꿈을 꿉니다. 이 때, 어떤 계획이나 잘 구체화된 목표 그리고 적절한 로드맵이 있다면, 한 해의 성장을 만들 수 있는 멋진 레시피를 갖는 것과 같죠.
이 글은 데이터 사이언스의 전문성을 갖출 수 있는 포트폴리오를 구축하기 위해 필요한 프레임워크, 리소스 그리고 프로젝트 아이디어를 충분히 제공해서 여러분의 계획을 더 풍성하게 하기 위해 작성되었습니다.
(잠깐. 이 로드맵은 저의 개인적인 경험을 기반으로 준비하였습니다. 이것이 전부가 아니며, 완전한 로드맵이라고도 할 수 없을 것입니다. 도메인에 따라, 관심 있는 연구분야에 따라 이 로드맵을 적용할 수 있을 것입니다. 그리고, 제가 개인적으로 선호하는 파이썬을 기반으로 글을 작성하였음을 미리 알려드립니다)

학습 로드맵이란 무엇일까요?
학습 로드맵은 정규 커리큘럼의 연장선입니다. 각 단계별로 얻고자 하는 것을 상세히 기술하고, 그것을 어떻게 측정할 수 있는지 그리고 어떻게 더 고도화시킬 수 있을지를 도식화합니다.
제가 개발한 로드맵은 각 단계마다 현업에서 적용되는 복잡성과 일반성을 기준으로 가중치를 부여했습니다. 또한 초보자가 연습과 프로젝트를 통해 완성시키는 수준까지 대략 걸리는 시간도 덧붙였습니다. 여기 업계에서의 복잡성과 적용 순서에 따라 높은 수준의 기술을 묘사하는 피라미드가 있습니다.
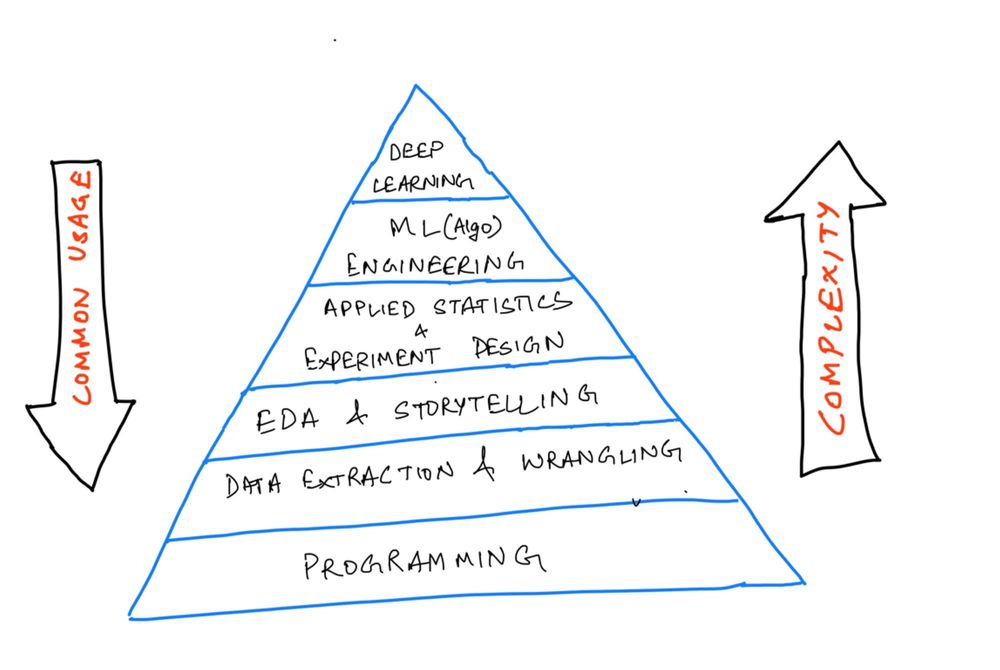
이것이 프레임워크의 기반이 될 것입니다. 이제 좀 더 구체적이고, 측정 가능한 세부사항들을 해나가기 위해 각각의 단계를 깊게 들여다보려 합니다.
특수성은 각 층별 주요한 주제와 그것을 마스터하는데 필요한 리소스를 검토하는 것에서 나옵니다.
우리는 실제 많은 프로젝트에서 학습한 주제를 적용함으로써 얻어진 지식을 측정할 수 있습니다. 저는 당신의 숙련도를 측정할 수 있는 몇 개의 프로젝트 아이디어, 포털, 플랫폼들을 추가했습니다.
중요 포인트: 하루에 하나씩 시작하세요. 하루에 비디오/블로그/챕터를 하나씩. 아래 내용이 다루는 범위는 정말 넓습니다. 시작부터 너무 주눅들지는 마세요!
자, 바닥부터 각 층을 자세히 파봅시다.
1. 프로그래밍 및 소프트웨어 엔지니어링
(예상 기간: 2-3개월)
먼저, 프로그래밍을 해야 합니다. 모든 데이터 과학 채용 조건은 적어도 하나의 언어에 대한 프로그래밍 기술을 요구해요.
알아야 할 프로그래밍 주제:
- 일반적인 데이터 구조 (데이터 타입, 리스트, 사전, 세트, 튜플), 함수 작성, 논리, 제어 흐름, 검색 및 정렬 알고리즘, 객체 지향 프로그래밍, 외부 라이브러리 작업 등
- SQL 스크립트: 조인, 집계, 서브쿼리 등을 사용하여 데이터베이스 조회
- 터미널 사용 능숙, Git 버전 제어와 GitHub 사용
파이썬 학습을 위한 리소스:
- learnpython.org [무료] – 초보자를 위한 무료 리소스. 웬만한 기본적인 프로그래밍은 다 다룹니다. 프로그래밍 주제를 나란히 옆에 두고 연습할 수 있는 대화형 쉘을 제공합니다.
- Kaggle [무료] – 파이썬 학습을 위한 무료 대화형 가이드. 데이터 과학에서 전반적으로 다루는 중요한 주제에 대한 짧은 튜토리얼입니다.
- Python certifications on freeCodeCamp [무료] – freeCodeCamp는 과학 컴퓨팅, 데이터 분석 및 머신러닝 등의 파이썬을 기반으로 하는 여러 자격증을 제공하고 있습니다.
- Python Course by freecodecamp on YouTube [무료] – 기본적인 개념을 연습하기 위해 따라갈 수 있는 5시간짜리 강의입니다.
- Intermediate python [무료] – freecodecamp.org. 에 게재된 Patrick의 무료 강의
- Coursera Python for Everybody Specialization [유료] – 초보자 수준의 개념부터 파이썬 데이터 구조, 웹 데이터 수집 및 파이썬을 이용한 데이터베이스 사용에 관한 전문가 과정입니다.
Git과 GitHub 학습을 위한 리소스:
- Guide for Git and GitHub [무료]: 버전 제어를 확실히 하기 위한 튜토리얼과 실습을 완료하세요. 앞으로 오픈 소스 프로젝트에 기여해야 할 때 도움이 될 것입니다.
- 여기는 FreeCodeCamp의 유튜브 채널 Git and GitHub crash course 과정입니다.
SQL 학습 리소스:
- FreeCodeCamp의 유튜브 채널 course on SQL and Databases 과정입니다.
- 캐글의 Intro to SQL 과 Advanced SQL 과정입니다.
- Treehouse에서 good introductory SQL course 과정을 제공합니다.
다양한 문제를 풀어보고 최소 2가지 이상의 프로젝트를 진행하면서 전문성을 측정하기:
- 많은 문제 풀기: HackerRank(초급자용) 및 LeetCode(쉽거나 중간 수준의 레벨 질문)
- 웹사이트/API 로 데이터 추출 — soundcloud.com과 같은 스크랩이 가능한 웹페이지로부터 데이터를 추출하여 파이썬 코드를 작성해봅니다. 추출된 데이터를 csv파일이나 데이터베이스에 저장합니다.
- 가위바위보, 실돌리기, 행맨, 주사위 굴리기 시뮬레이터, tic-tac-toe와 같은 게임을 만들어 보세요.
- 유튜브 비디오 다운로더, 웹사이트 차단기, 음악 재생, 표절 검사 등과 같은 간단한 웹앱을 만들어 보세요.
이러한 프로젝트를 GitHub 페이지에 배포하거나 Git 사용을 학습하기 위해 GitHub에 코드를 간단하게 올려보는 것도 좋습니다.
2. 데이터를 추출하고 처리하는 방법
(예상 기간: 2개월)
데이터 사이언스의 중요한 부분은 문제를 해결할 수 있는 적절한 데이터를 찾는 데 중점을 두고 있습니다. 스크래핑, APIs, 데이터베이스 그리고 공공 데이터 등의 여러 합법적인 소스로부터 데이터를 수집할 수 있습니다.
데이터가 있다면, 분석가는 데이터 프레임을 스스로 처리하고 다차원 배열을 작업하며 기술 및 과학적 계산을 하고 데이터 집계를 위한 데이터프레임을 만들어 낼 수 있습니다.
‘현실’에서 사용되는 데이터는 잘 정리되어 있거나 포맷화되어 있지 않습니다. Python에서 사용하는 Pandas와 Numpy는 정리되지 않은 데이터부터 분석 가능한 데이터로 만들어주는 라이브러리입니다.
파이썬 프로그램이 익숙하다면 Pandas와 Numpy 같은 라이브러리를 사용하는 과정을 들어보세요.
데이터 추출과 정제를 배울 수 있는 리소스:
- Numpy, Pandas, matplotlib, and seaborn를 배울 수 있는 프리코드캠프 [무료]
- HackerEart의 data manipulation with NumPy and Pandas in Python 예제 튜토리얼
- Kaggle pandas tutorial [무료] – 일반적으로 데이터 작업을 할 때 사용하게 되는 짧고 간결한 튜토리얼
- Data Cleaning course by Kaggle.
- Coursera course on Introduction to Data Science in Python – Applied Data Science with Python Specialization. 의 첫 실습 강의입니다.
데이터 수집 프로젝트 아이디어:
- 웹사이트/API (공개용 데이터)를 수집하고 데이터를 변환하여 다른 소스로부터 집계된 파일 또는 테이블(DB)로 저장합니다. 예제 API는 TMDB, quandl, Twitter API 등이 있습니다.
- 공개된 데이터를 선택하여 데이터 셋과 도메인을 보고 추구하고 싶은 것들에 대한 질문을 정의해 보세요. Pandas와 Numpy를 이용하여 질문에 맞는 답을 찾기 위한 데이터를 만들어 보세요.
3. 데이터 해석과 비즈니스 통찰, 스토리텔링 학습
(예상 기간: 2-3개월)
다음으로 마스터해야 할 단계는 데이터 분석과 스토리텔링입니다. 데이터로부터 인사이트를 도출하고 간단한 용어와 시각화로 경영진에게 전달하는 것은 데이터 분석의 핵심입니다.
스토리텔링은 훌륭한 커뮤니케이션 능력과 함께 데이터 시각화하는 데 유능함이 요구되는 부분입니다.
배워야 할 구체적인 데이터 탐색 및 스토리텔링 주제는 다음과 같습니다:
- 담대한 데이터 분석 – 문제의 정의, 결측치 처리, 이상값, 형식 변환, 필터링, 단변량과 다변량 분석
- 데이터 시각화 – matplotlib, seaborn 및 plotly와 같은 라이브러리 사용하여 데이터를 플로팅합니다. 데이터로부터 찾은 결과를 전달하기 위해 적절한 차트를 선택할 줄 알아야 합니다.
- 대시보드 개발 – 분석가 중 대부분은 엑셀 뿐만 아니라 Power BI나 태블로와 같은 전문 툴을 사용하여 경영진이 의사 결정을 내리기 위한 데이터 요약 및 집계하는 대시보드를 구축합니다.
- 비즈니스 통찰 – 실제 비즈니스 지표를 타겟으로 하는 적절한 질문에 답을 해보세요. 명확하고 간결한 리포트, 블로그, 발표 자료 작성을 연습해보세요.
데이터 분석에 학습할 수 있는 리소스:
- free course on the freeCodeCamp 유튜브 채널에서 파이썬을 이용한 데이터 분석 과정을 들어보세요
- Data Analysis with Python – 코세라에서 IBM이 제공하는 데이터 처리, 탐색 그리고 간단한 모델 개발을 파이썬으로 다뤄 볼 수 있습니다.
- Data Visualization – 캐글에서 제공하며 일반적으로 사용하는 모든 플롯을 연습해볼 수 있는 대화형 수업입니다.
- 다음과 같은 책으로 프로덕트의 감각과 비즈니스 통찰을 키워보세요: Measure what matters(국내: 존 도어의 OKR), Decode and conquer, Cracking the PM interview(국내: PM 인터뷰의 모든 것).
데이터 분석 프로젝트 아이디어:
- 수익성 있는 영화를 만들기 위한 공식을 찾기 위해 영화 데이터 셋을 탐색하고 의료, 금융, WHO, 지난 인구조사, 경제 등과 같은 데이터를 사용해봅니다.
- 위에 언급된 리소스를 사용하여 대시보드(주피터 노트북, 엑셀, 태블로)를 구축해보세요.
4. 데이터 엔지니어링 학습
(예상 기간: 4-5개월)
데이터 엔지니어링은 빅데이터 기업에서 엔지니어들과 데이터 과학자들이 연구를 하기 위해 처리된 데이터에 접근할 수 있도록 R&D팀을 지원하고 있습니다. 그 자체로 한 분야이고요. 만약 당신이 어떤 문제를 볼 때 통계적인 알고리즘에 중점을 두고 있다면 당신은 이 부분을 건너 뛰어도 됩니다.
데이터 엔지니어의 책임은 효과적인 데이터 아키텍쳐 구축, 데이터 처리 간소화 및 대규모 데이터 시스템을 유지하는 데 있습니다.
엔지니어는 ETL 파이프라인, 자동 파일 시스템 작업 및 고성능을 내기 위한 데이터베이스 최적화를 위해 Shell(CLI), SQL, Python/Scala를 사용하고 있습니다.
또 다른 중요한 능력은 AWS, Goolgle 클라우드 플랫폼, Microsoft Azure 등과 같은 클라우드 서비스를 기반으로 퍼포먼스를 내는 데이터 아키텍쳐를 구현하는 것입니다.
데이터 엔지니어링 학습을 위한 리소스:
- Data Engineering Nanodegree by Udacity – 컴파일된 리소스 리스트에 관해는 이보다 더 좋은 체계적인 데이터 엔지니어링 과정을 본 적이 없습니다. 처음부터 주요한 컨셉을 모두 다룹니다.
- Data Engineering, Big Data, and Machine Learning on GCP Specialization – 완성된 데이터 솔루션 구축을 위해 코세라에서는 GCP의 모든 주요한 API와 서비스를 가지고 구글이 제공하는 전문 과정을 통해 완성할 수 있습니다.
데이터 엔지니어링 준비를 위한 인증:
– AWS Certified Machine Learning (300불) – AWS에서 제공하는 검증된 시험, 당신의 프로필을 채워줍니다(비록 보장되는 건 아니지만요). 그리고 AWS 서비스와 ML에 대한 적절한 이해도를 요구합니다.
– Professional Data Engineer – GCP에서 제공하는 인증입니다. 마찬가지로 검증된 시험이며, 데이터 처리 시스템 설계와 작업 환경에서 머신러닝 모델 배포 및 품질과 자동화를 보장하는 지 역량을 평가합니다.
5. 응용통계와 수학을 학습하는 방법
(예상 기간: 4-5개월)
통계적 모델은 데이터 사이언스의 중심입니다. 거의 모든 데이터 사이언스는 주로 기술적 및 추론 통계에 중점을 두고 있습니다.
사람들은 종종 알고리즘의 작동을 설명하는 통계 및 수학적 방법론의 명확한 이해 없이 머신러닝 알고리즘 코딩을 시작합니다. 물론, 이것은 최선의 방법이 아닙니다.
응용통계와 수학에 중점을 두어야 할 토픽들:
- 기초 통계량 – 데이터를 요약할 수 있다는 것은 강력합니다. (항상은 아니지만요). 데이터를 설명하는 위치값(평균, 중간값, 모드, 가중 통계, 구간 통계), 변동성에 대해 공부하세요.
- 추론 통계 — 가설을 세우기, A/B 테스트, 비즈니스 지표 정의하기, 수집된 데이터, 신뢰구간, p-value 그리고 유의확률을 사용하는 실험 결과 분석하기
- 선형대수와 머신러닝에서의 손실함수, 기울기, 최적화를 이해하기 위한 단/다변량 미적분을 알아두세요.
통계와 수학을 배우는 리소스:
- Learn college-level statistics freeCodeCamp 유투브 채널에서 무료로 공개된 8시간 과정입니다..
- [도서] Practical statistics for data science (매우 추천) — 명확하고 간결한 적용/예제를 통해 중요한 모든 통계 방법론에 대해서 알 수 있습니다.
- [도서] Naked Statistics (번역: 벌거벗은 통계학)– 기술적이지는 않지만 우리의 일상, 스포츠, 추천 시스템 그리고 다른 사례로 통계를 이해하기 위한 상세 가이드
- Statistical thinking in Python — 통계적 사고를 시작하는 데 도움이 되는 기초 과정. 두번째 과정도 있습니다.
- Intro to Descriptive Statistics — Udacity에서 제공합니다. 위치값과 변동성(표준 편차, 분산, MAD) 등 널리 사용되고 있는 것을 설명하는 영상 강의로 구성되어 있습니다.
- Inferential Statistics, Udacity – 당신이 직관적으로 바로 보이지 않는 데이터로부터 결론을 도출하는 방법을 교육하는 영상 강의로 구성되어 있습니다. 가설을 만들고 t-test, ANOVA 및 회귀분석에 중점을 두고 있습니다.
- 그리고 여기 데이터 과학을 올바른 길로 시작할 수 있게 도와주는, 제가 쓴 guide to statistics for data science도 있습니다.
통계 프로젝트 아이디어:
- 위의 강의에서 제공된 예제들을 풀어보세요. 그리고 당신이 통계적 관점에서 적용해 볼 수 있는 많은 공공 데이터 셋으로 경험해보시기 바랍니다. 이런 질문을 해보세요. “보스턴에서 출산하는 산모들의 평균 나이가 25살 이상인지 유의수준 0.05 하에서 구하시오.”
- 앱을 통해 만나고 질문에 답함으로써 동료/그룹/강좌와 함께 실험을 설계하고 실행해 보세요. 만약 일정 시간이 흐른 후 충분한 양의 데이터가 있다면 수집된 데이터로 통계적 방법을 실행해보세요.
- 주가, 암호화폐를 분석해보고 평균 수익 및 다른 지표에 대한 가설을 만들어 보세요. 당신이 귀무가설을 기각할 수 있는지 혹은 임계값을 사용하여 기각할 수 있는지 결정해보세요.
6. 머신러닝과 AI를 학습하는 방법
(예상 기간: 4-5개월)
이때까지 단련시키면서 앞서 언급한 모든 주요한 개념을 살펴봤다면 당신은 이제 멋진 ML 알고리즘을 시작해볼 준비가 되었습니다.
학습에는 3가지 주요한 유형이 있습니다.
- 지도학습 – 회귀분석과 분류 문제를 포함합니다. 단순회귀분석, 다중회귀분석, 다항회귀분석, 나이브 베이즈, 로지스틱 회귀분석, KNNs, 트리 및 앙상블 모델을 공부하세요. 평가 지표도 배워야 합니다.
- 비지도학습 – 클러스터링과 차원 축소 두가지는 비지도학습 적용에 널리 사용되고 있습니다. PCA, K-means, 클러스터링, 계층적 클러스터링, 가우시안 혼합 모형에 대해 깊게 파보세요.
- 강화학습(스킵 가능*) – 자기 보상 시스템을 구축하는 데 도움이 됩니다. 보상을 최적 하고 TF-Agents 라이브러리를 사용하고 Deep Q-networks등과 같은 것을 배워보세요.
대부분의 ML 프로젝트는 이 블로그에서 설명하는 많은 작업을 마스터해야 합니다.
머신러닝을 학습하는 리소스:
- Machine learning in Python with ScikitLearn FreeCode Camp 유투브 채널에서 무료로 하는 전 과정입니다.
- [도서] Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition (번역: 핸즈온 머신러닝)- 제가 가장 좋아하는 머신러닝 책 중 하나입니다. 이론적인 수학 공식 유도 뿐만 아니라 예제를 통한 알고리즘 구현을 보여줍니다. 각 챕터 마지막에 주어진 예제를 풀어봐야 합니다.
- Machine Learning Course by Andrew Ng – 머신러닝을 배운다면 모두가 한 번은 듣는 과정이죠.
- Introduction to Machine Learning – Kaggle에서 제공하는 대화형 과정입니다.
- Intro to Game AI and Reinforcement Learning – 강화 학습에 관한 Kaggle의 또다른 대화형 과정입니다.
Deep Learning Specialization by deeplearning.ai
딥러닝을 깊게 파는 데 관심이 있는 사람들을 위해, deeplearning.ai와 Hands-ON 책에서 제공하는 전문과정을 완성함으로써 시작해 볼 수 있습니다. 컴퓨터 비전이나 NLP 문제를 해결하는데 계획이 없다면 데이터 사이언스 관점에서는 중요하지 않습니다.
딥러닝은 그 분야만의 로드맵이 필요합니다.
당신의 학습 진도를 체크하세요.
Notion에 여러분을 위한 학습 추적기를 만들어 보았습니다. 여러분의 필요에 따라 맞춤화 해볼 수 있고 진도를 추적하고 모든 자료와 프로젝트에 쉽게 접근할 수 있습니다.
https://www.notion.so/Data-Science-learning-tracker-0d3c503280d744acb1b862a1ddd8344e
또한, 여기 영상 버전도 있습니다.
제가 새로운 토픽을 추가하거나 어떤 것이든 이름을 다시 붙이고 싶다면 언제든지 이 블로그 또는 비디오에 의견을 주십시오. 또한 어떤 카테고리의 튜토리얼 프로젝트를 진행하고 싶은지 제게 알려주세요.
- 같이 읽기: 데이터 사이언티스트의 길
- 번역: 벨 (객원) / 편집: 뤽
- 원문: 프리코드캠프 https://www.freecodecamp.org/news/data-science-learning-roadmap/

좋은 번역 감사합니다
좋아요좋아요